Tutorial: How to use biaslyze to test pre-trained hate speech detection models
You can also use biaslyze to test pre-trained models for bias indications. This notebook will show you how using a hate speech classifier model from huggingface.
Installation
Start by installing the biaslyze python package from pypi using:
import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.metrics import accuracy_score
Load and prepare data
To test the model, we need to use some data. We use the dataset from https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge.
| id | comment_text | toxic | severe_toxic | obscene | threat | insult | identity_hate | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0000997932d777bf | Explanation\nWhy the edits made under my usern... | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 000103f0d9cfb60f | D'aww! He matches this background colour I'm s... | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 000113f07ec002fd | Hey man, I'm really not trying to edit war. It... | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0001b41b1c6bb37e | "\nMore\nI can't make any real suggestions on ... | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0001d958c54c6e35 | You, sir, are my hero. Any chance you remember... | 0 | 0 | 0 | 0 | 0 | 0 |
Test a pre-trained hate speech detection model
Get a pre-trained model of your choice that you want to check for possible bias. In this case we will test the HateXplain model which we can get from huggingface hub. This binary model classifies text as "Abusive" (Hatespeech and Offensive) or "Normal" text.
from transformers import pipeline
from typing import List
from biaslyze.bias_detectors import CounterfactualBiasDetector
To make biaslyze work with the model we need to wrap it in a class that has a predict_proba method. The method should take a list of texts, run it through the pre-trained model and return a numpy array of shape (n_samples, n_classes) with the predicted probabilities for each class. In this case we have two classes: "Normal" and "Abusive".
class HateSpeechClf:
def __init__(self):
self._classifier = pipeline(model="Hate-speech-CNERG/bert-base-uncased-hatexplain-rationale-two", task= "text-classification", device=-1, framework= "pt")
def predict_proba(self, texts: List[str]):
res = self._classifier(texts, top_k=None, truncation=True, batch_size=4)
return np.array([np.array([d[0]["score"], d[1]["score"]]) for d in res])
Now we can check the model for bias indications within the relevant concepts provided by biaslyze. If you want to work with your own concepts or add to the given ones, please check out the tutorial on how to use custom concepts.
counterfactual_detection_results = bias_detector.process(
texts=df.comment_text.sample(10000),
predict_func=hate_clf.predict_proba,
concepts_to_consider=["gender"], # , "religion", "nationality", "ethnicity"]
max_counterfactual_samples=None,
max_counterfactual_samples_per_text = 2
)
2023-08-11 10:51:49.666 | INFO | biaslyze.concept_detectors:detect:35 - Started keyword-based concept detection on 10000 texts...
100%|███████████████████████████████████████████████████████████████████| 10000/10000 [00:00<00:00, 10160.91it/s]
2023-08-11 10:51:50.653 | INFO | biaslyze.concept_detectors:detect:51 - Done. Found 8990 texts with protected concepts.
2023-08-11 10:51:50.654 | INFO | biaslyze.bias_detectors.counterfactual_biasdetector:process:137 - Processing concept gender...
100%|███████████████████████████████████████████████████████████████████████| 8990/8990 [00:32<00:00, 276.02it/s]
100%|██████████████████████████████████████████████████████████████████████| 8990/8990 [00:05<00:00, 1795.13it/s]
2023-08-11 10:52:28.236 | INFO | biaslyze.bias_detectors.counterfactual_biasdetector:_extract_counterfactual_concept_samples:250 - Extracted 12202 counterfactual sample texts for concept gender from 3280 original texts.
100%|█████████████████████████████████████████████████████████████████████████| 81/81 [2:30:22<00:00, 111.39s/it]
2023-08-11 13:22:50.903 | INFO | biaslyze.bias_detectors.counterfactual_biasdetector:process:197 - DONE
Looking at the results
CONTENT WARNING: Be aware that this section contains content that is disturbing, offensive, and can propagate historical and current stereotypes.
Now we can look at the resulting scores.
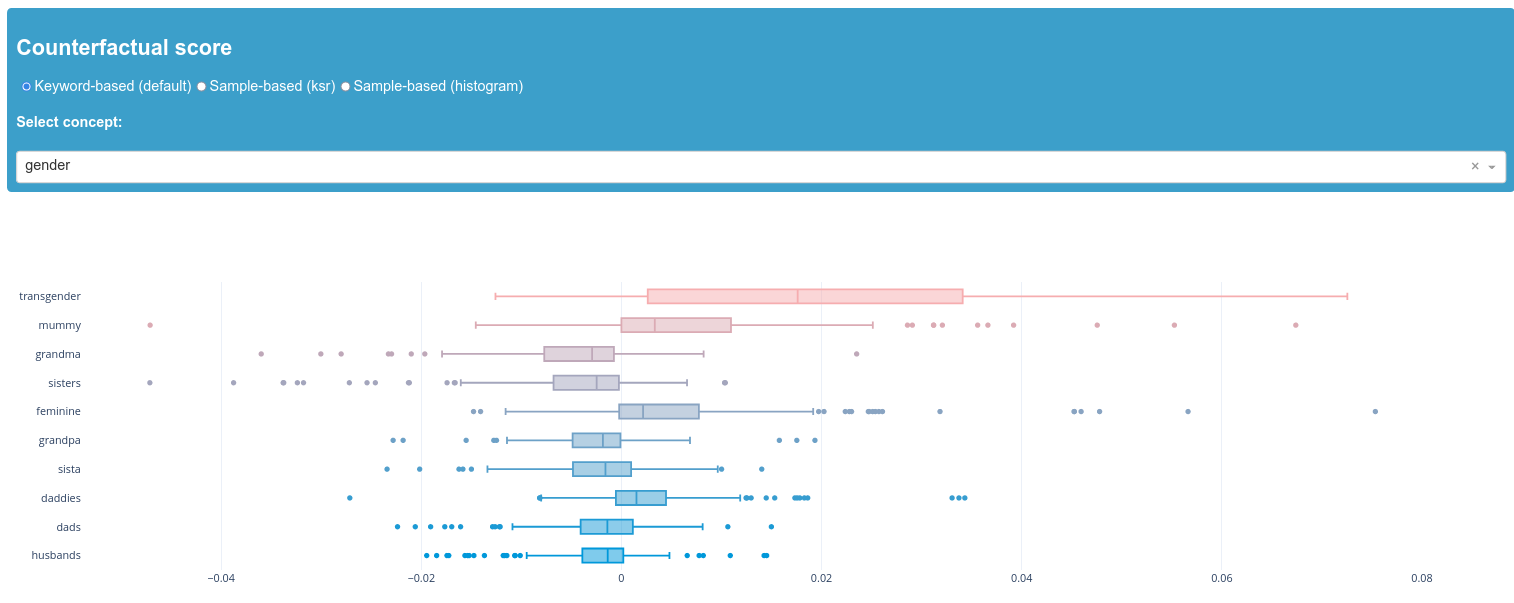
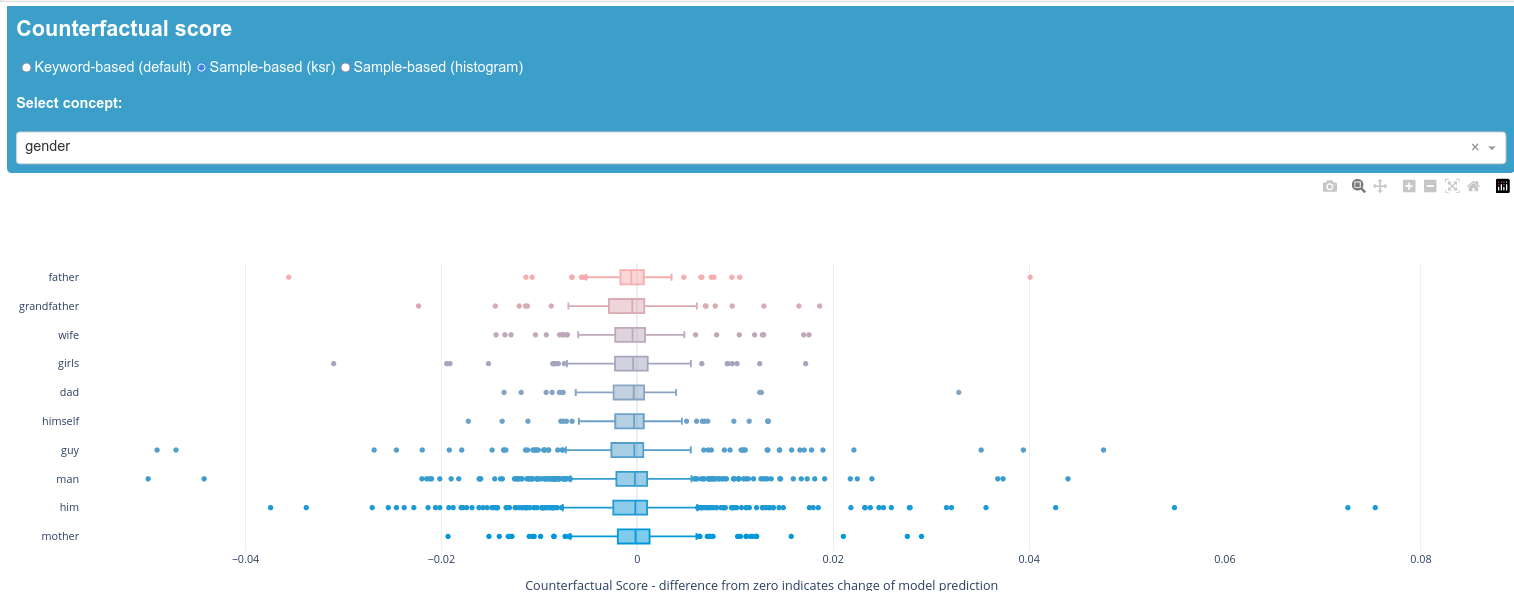
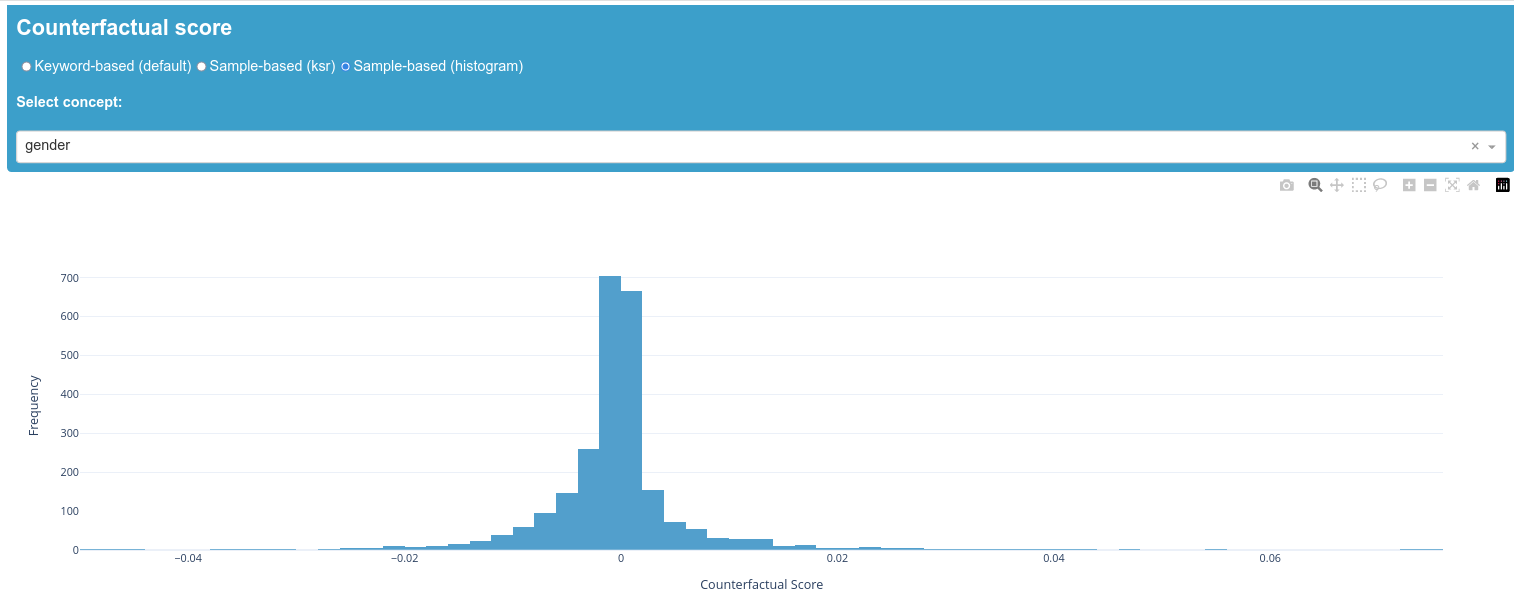
The keyword-based scores show relatively low deviation from our zero value, which indicates that the individual keywords do not have a lot of impact on the prediction of the model. "Transgender" is the only exception here. It is therefore advisable to take a look at the corresponding samples and the ksr-score in order to understand how this outlier is caused. We can see that "transgender" does not appear among the top 50 scores of the ksr-scores, which could indicate a representation problem causing this keyword to perform differently. It is possible that the keyword does not appear in the dictionary.
Overall, there is no clear evidence that a keyword or concept impacts the prediction of the model strongly and that there is a corresponding bias. However, it is important to note that a full assessment of whether the model is biased is highly dependent on the application context which must always be taken into account when interpreting the results.